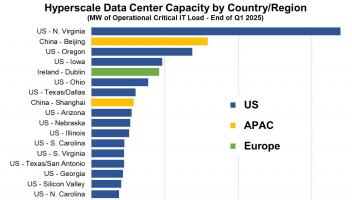
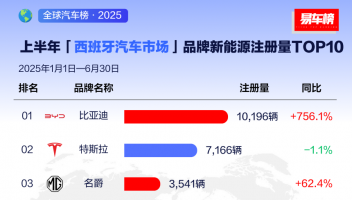
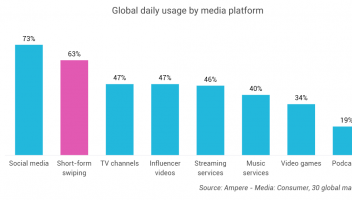
9月19日消息,继SuperCLUE中文大模型评测基准8月榜单发布之后,国内又一权威评测体系FlagEval(天秤)公布最新9月榜单评测结果。
FlagEval(天秤)是北京智源人工智能研究院推出的大模型评测体系及开放平台,旨在建立科学、公正、开放的评测基准、方法、工具集,协助研究人员全方位评估基础模型及训练算法的性能。FlagEval 大语言模型评测体系当前包含6大评测任务,近30个评测数据集,超10万道评测题目。
据悉,在9月评测中,FlagEval进行了评测框架升级,细化「安全与价值观」与「推理能力」。依据最新版的能力框架,FlagEval 团队同步更新了智源自建的 Chinese Linguistics & Cognition Challenge (CLCC) 主观评测数据集题库v2.0,题目数量扩充3倍,采用“多人‘背靠背’评测+第三方仲裁”的方式保证评测结果的一致性。
基于最新 CLCC v2.0主观评测数据集,FlagEval(天秤)9月榜重点评测了近期大热的 7 个开源对话模型。从整体结果来看,Baichuan2-13b-chat、Qwen-7b-chat、Baichuan2-7b-chat名列前茅,准确率均超过 65%。
在基座模型榜单中,Baichuan 2、Qwen、InternLM、Aquila 的客观评测结果表现均超越同参数量级的 Llama 及 Llama2 模型。
在 SFT 模型榜单中,Baichuan2-13B-chat、YuLan-Chat-2-13B、AquilaChat-7B 名列前三。
另外,值得注意的是,在客观评测两个榜单中,Baichuan 2均表现出优异性能,基础模型测试在中英文领域均全面超越Llama2。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )