标题:Meta新模型WebSSL:视觉学习的颠覆性认知
Meta公司近日发布的WebSSL系列模型,引发了业界对于视觉学习领域的深度思考。这一系列模型以无语言监督学习为特色,旨在探索视觉自监督学习的潜力。与OpenAI的CLIP相比,WebSSL模型在多个维度上展现了其独特的优势和潜力。
首先,WebSSL模型采用了联合嵌入学习(DINOv2)和掩码建模(MAE)两种视觉自监督学习范式。模型仅使用MetaCLIP数据集中的20亿张图像子集进行训练,排除了语言监督的影响。这一设计思路,使得模型能够在纯视觉环境下进行训练,从而避免了数据和模型规模限制带来的挑战。
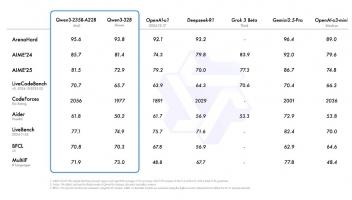
其次,WebSSL模型在五个容量层级(ViT-1B 至 ViT-7B)上进行了训练,评估基于Cambrian-1基准测试,涵盖了通用视觉理解、知识推理、OCR和图表解读等16个视觉问答任务。这一大规模训练和评估过程,揭示了参数规模对模型性能的影响,以及模型在无语言监督下的表现潜力。
值得注意的是,WebSSL模型在OCR和图表任务中的表现尤为突出。通过仅用1.3%的富文本图像进行训练,WebSSL模型在OCRBench和ChartQA任务中的提升高达13.6%。这一结果无疑挑战了现有的视觉学习模型在无语言监督下的表现极限。
此外,高分辨率(518px)微调进一步缩小了与SigLIP等高分辨率模型的差距,在文档任务中表现尤为出色。这表明WebSSL模型在处理高分辨率图像时,具有更强的适应性和表现力。
更为值得一提的是,WebSSL模型在传统基准测试(如ImageNet-1k分类、ADE20K分割)上保持强劲表现,部分场景甚至优于MetaCLIP和DINOv2。这一结果无疑增强了我们对WebSSL模型的信心,也让我们看到了其在未来视觉学习领域的无限可能。
那么,WebSSL模型能否挑战OpenAI的CLIP呢?从目前的结果来看,WebSSL在无语言监督下的表现潜力巨大,其在OCR和图表任务中的表现甚至超越了CLIP。然而,我们也需要认识到,CLIP作为一款里程碑式的模型,其在语言和视觉的双模态特性上具有无可比拟的优势。因此,WebSSL要想挑战CLIP,需要在保持其纯视觉特性的同时,进一步挖掘其语言特性,以实现更广泛的应用和更深入的理解。
总的来说,Meta的WebSSL模型为我们提供了一个全新的视角来理解和处理视觉数据。通过无语言监督的学习方式,WebSSL有望为我们带来更强大、更灵活的视觉表征学习模型。我们期待着WebSSL在未来能够带来更多的惊喜和突破。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )