
微软亚洲研究院副院长刘铁岩
可持续发展是一个非常重要的主题,无论是环保、健康、能源和材料,都与人类的生存和发展息息相关。随着工业的发展和科技的进步,我们看到大气、水质、土壤受到了严重的破坏和污染,维护生态平衡、保护自然环境,确保社会的可持续发展已经成为人类生存发展的根本性问题。一直以来,微软在环保、节能方面投入了大量精力,而利用AI等技术解决环保、能源问题,实现可持续发展,也是微软亚洲研究院的一个重要研究课题。
人工智能助力环保,潜力巨大
提到环保,大气污染治理是其中一个主要方向。此前,微软承诺到2030年实现负碳排放,到2050年,消除微软自1975年成立以来的碳排放量总和,包括直接排放或因用电产生的碳排放,立足于科学和数学,为微软的碳足迹负责。同时承诺未来四年内投入10亿美元设立一项气候创新基金,帮助加速全球碳减排、碳捕获和碳消除技术的发展。
现阶段一些大气污染治理方式取得了不错的效果,不过在精准度方面还有待进一步提高,不然很容易导致大气污染治理和经济发展之间产生难以调和的矛盾。而实现精准的大气污染治理,面临两个挑战:首先,要知道当前各个地区具体的污染物排放情况,构建一份详细的排放清单;其次,要了解针对某一类特殊排放物或者污染源进行处理之后,它们在多大程度上、会以何种方式去影响最终空气的质量。
两个问题看似简单,实现起来并不容易。以排放清单估计为例,由于污染排放源复杂且不断变化,我们需要理解各种排放物在各个地区每小时的变化,但又无法在每个排放源旁都摆放一个传感器,去采集细粒度、高精度的排放数据。因此当前的排放清单估计,严重依赖于专家根据宏观经济信息进行排放普查,费时费力,缺乏精度保障。据专家估计,该精度只有60%左右。
排放估计机器学习模型:误差降低65%
利用人工智能、机器学习技术自动估计精确的排放清单,可以节省大量人力成本,并且为决策提供更及时、有力的支撑。
首先,我们来构建一个机器学习模型,从大气的污染物分布出发,去预测排放清单。通常我们会需要大量训练数据,这些数据需要包含不同类型的大气污染物分布所对应的排放清单,但这正是我们要通过AI去解决的问题,因为现实中我们无法采集到细粒度、高精度的排放清单,训练数据在这里出现了“鸡生蛋、蛋生鸡”的尴尬局面。
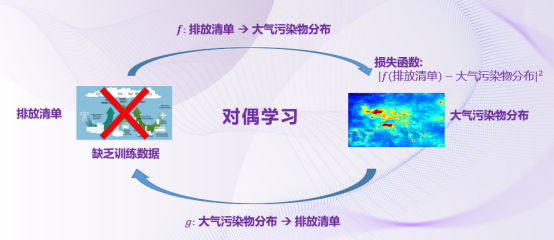
利用人工智能实现排放清单估算
我们注意到,这个问题的背后有一个反向问题,我们可以从排放清单出发,通过推演获得大气中污染物的分布,这个问题的难度则要低得多。这里刚好可以用到微软亚洲研究院近年来所提出的“对偶学习”思想。利用对偶学习,从大气污染物分布出发,经过排放清单,再回到大气污染物分布,形成学习闭环,我们就可以利用对大气污染物预测的误差,来驱动整个学习过程,最终获得排放清单估计模型。
事实上,在环境科学领域,从排放清单推演出大气污染物的分布,已经有一个被广泛使用的系统,叫做化学输送模型(CTM),我们可以把CTM当作对偶学习闭环中的一环,来实现学习过程。不过CTM系统有个小问题,它是一个离散系统,不可求导,因此我们提出构建一个连续可导的函数,用它来逼近CTM系统。考虑到CTM中有非常复杂的化学反应,以及时空的对流扩散等过程,我们选用了一个相对复杂的复合神经网络来实现。在该网络里,我们用CNN实现了对地理位置的编码,用LSTM循环神经网络对时域信息进行编码,用U-Net实现对空间信息的建模。
在过去的一年,我们与清华大学的科学家一起,基于1500个观测站点的排放数据,评测了排放估计模型。实验表明,相比之前的专家估计,机器学习模型不仅节省了大量的人力成本,还把相对的估计误差降低了65%,极大提升了排放清单估计模型的精度。
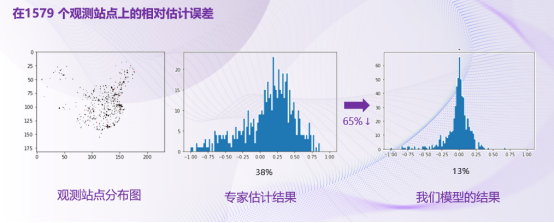
排放估计模型实验结果
一次CTM仿真,即可获得精准的大气化学反应曲面
当有了相对准确的排放清单估计之后,下一个问题就是,基于这个清单对其中的某种排放物或污染源进行控制,最终会如何影响大气污染物的分布?如果每一次排放控制都经过一次CTM仿真才能获得大气污染物的变化,那几乎要穷举所有的排放状况,才能全面掌握这个问题,这显然不可行。
人们通常采用基于采样的近似曲面估计方法去构建大气化学反应的曲面,可以有效降低CTM仿真的复杂度,但这个曲面的精度和构建曲面时所需要的样本点数目密切相关,而在实践中想得到一个相对细致的大气化学反应曲面,通常要采集几百万个样本点,其中的运算复杂度非常高。
微软亚洲研究院和清华大学合作研发了全新的方法,只需要经过一次CTM仿真就可以获得精准的大气化学反应曲面,这个算法背后的特别之处在于我们对于大气化学反应机理的深刻认识。大气中化学反应通常是可逆的,而且生成物的浓度与反应物浓度之间存在一定的定量关系。这个关系与只依赖于外部条件的一个化学平衡常数K有关,还与一个反应关系函数R有关。因此,我们不需要对每种反应物的浓度进行CTM仿真,只需要在一个基准浓度的CTM仿真基础上,在外部条件不变的前提下,利用这个反应关系函数R直接估计出各种情况下生成物的浓度。在实际操作中,我们用神经网络来对反应关系函数R进行建模,再用一定量的训练数据去学习这个神经网络的参数即可。
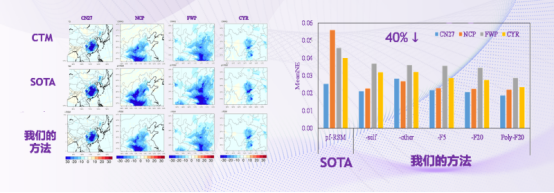
预测误差从4.1%下降到2.5%
由于传统基于采样点来逼近化学反应曲面,会受到采样点数目的限制,无法实现完全精准的曲面拟合。而我们的方法利用大气化学反应的本质规律,不存在采样点带来的近似误差。通过测试,新方法不仅节省了用于CTM仿真的大量计算资源,而且在预测精度上还将相对误差降低了近40%。目前,该研究成果已经发表在环境科学领域顶级期刊《环境科学与技术》上,并已被应用于大气污染治理的实战。
关注AI背后的能耗,算法可以更精巧
人工智能是一把双刃剑,一方面它可以帮助解决可持续发展所面临的问题,如前文提到的大气污染与能源损耗,另一方面,人工智能模型的训练本身也要消耗大量资源。近些年人工智能领域有一个令人担忧的现象,就是所谓大力出奇迹——人们过度依赖大模型、大数据去解决人工智能的精度问题,这不可避免要消耗大量能源。
例如,围棋选手AlphaGo在战胜人类世界冠军的背后,是上千块CPU和上百个GPU的消耗;自然语言预处理技术Bert背后需要几十个TPU的支撑,才能够完成一个有效的训练;用于图像生成的大规模对抗生成网络也要消耗几百个GPU。每一个人工智能系统本身,就是资源消耗大户,AI自身的可持续发展问题又该如何解决呢?
作为研究人员,我们不禁自问:人工智能要发挥威力,一定需要消耗巨大的计算资源吗?过去的5年里,我们基于这样的思路,开发了一批高效实用的低功耗人工智能技术,包括让计算复杂度与主题数目无关的高效主题模型LightLDA,只需300个CPU内核,就训练出了比以往要用上万个内核才能训练出的模型还要大若干数量级的新模型;速度快、准确率高、内存要求低、分布式支持还可轻松快速处理海量数据的LightGBM算法,实现了比市场上最好的梯度决策树算法还要快一个数量级的新算法;兼具快速、鲁棒、可控等优点的语音合成算法FastSpeech,将性能最好的语音合成引擎提速了近270倍,而且只需要使用低端GPU就可以实现实时的语音合成服务。
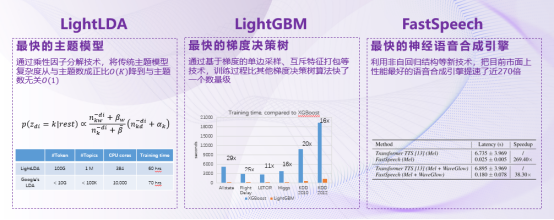
微软亚洲研究院高效的人工智能算法
这些新技术因为低功耗、高效率,或是可以在同样时间内训练出性能更好的机器学习模型,已经应用于微软的多个产品中,也受到了外界的广泛关注。LightLDA模型为必应搜索引擎的上下文广告提供了精细匹配的支持,增加了广告拍卖的密度;LightGBM算法极大程度上推进了人工智能算法的平民化,受到了GitHub社区的青睐,同时也是必应搜索引擎后台的核心技术之一;Fastspeech算法在微软Azure的认知服务中支持15种语言的语音合成,也是市场上语音处理开源软件的主流技术。
这几个来自微软亚洲研究院的高效算法只是一个开始,为了人工智能的可持续发展,我们不仅要关心算法的性能、精度,还要注意其背后的能耗问题。也希望这些算法设计的新角度,可以给大家一些启示,去聚焦精巧的算法创新,做到事半功倍,以多快好省的方式,实现真正可持续发展的人工智能。
只有当人工智能算法本身具有可持续发展性,它才有资格、有能力去助力其他关键领域的技术转型。我们热切地呼吁人工智能领域的研究人员和从业者共同努力、精诚合作,用可持续发展的人工智能技术去真正推动人类社会的可持续发展。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















