
序:鲁迅先生说:第一个吃螃蟹的人是令人佩服的,不是勇士谁敢去吃它呢? 虽然分布式改造在银行业是大势所趋,但在国有大行,中国邮政储蓄银行(以下简称邮储银行)却是第一个迈出这一步的。
今年4月,邮储银行新一代分布式核心系统投产的消息引发了业内广泛关注,这是国有六大行首个落地的分布式金融新核心。虽然分布式架构已经在互联网IT技术领域广泛应用并积累了大量实践经验,但在银行业,目前分布式实践仍存在不少问题,而以邮储银行国有大行的巨大体量构建新核心的难度更是成指数级上升。
邮储银行为什么要迎难而上来构建新核心?新核心构建路径是怎样的?最终落地成果如何?相信很多人都比较好奇,IT168基于公开资料的研究整理,希望对同业转型能够提供一些参考。
百年邮储的新时代挑战
邮储银行可追溯至1919年开办的邮政储金业务,至今已有百年历史。邮储银行依托“自营+代理”的独特运营模式,已经发展成为中国网点数量众多、地域覆盖广阔、服务深度下沉的国有大型商业银行,根据其2020年财报,邮储银行有近40000个网点,覆盖全国99%的县(市),服务个人客户超6亿户。
银行事关民生大计,于国家发展而言,经济是肌体,金融是血脉,两者共生共荣。在数字经济时代,商业银行数字化转型大幕早已拉开,目前,中国的银行业正处于数字化转型的关键时期,在数字金融生态和生态互联开放的背景下客户需求日趋个性化、多元化,邮储银行在思考如何通过数字化构建持久和差异化的核心竞争能力。
据悉,邮储银行传统的核心系统采用经典的IOE架构搭建而成,支撑了邮储银行初期信息化,电子金融。但随着金融服务在线化,小额交易频次越来越高等这些服务场景的变化,对传统的核心系统带来了巨烈的冲击,尤其在交易热点时段,现有系统弹性不足,造成交易缓慢,严重影响用户体验和邮储的品牌形象。商业软件架构与技术封闭,迭代慢,在应对金融创新乏力,无法继续支撑邮储银行向前发展。原有的核心系统已经到了支撑能力的天花板,因此,新核心的构建迫在眉睫。
在今年华为智慧金融峰会上,邮储银行首席信息官牛新庄回顾新核心的建设时曾指出:“核心系统是一家银行的引擎、发动机,打造一个强大的引擎、发动机,才能够为客户提供更加极致的服务。”他进一步指出,银行数字化转型的目的就是要打造以用户为中心,面向用户体验,对内提高效率,梳理产品和流程,提升效益。所以,邮储银行在2019年,从核心系统入手,构建了新一代核心系统。
构建新核心求破局
2019年年初邮储银行开始启动下一代金融核心的预研,对于新核心的需求目标很明确,一是支持业务创新,打造核心竞争力。二是突破系统瓶颈,实现自主可控。三是顺应分布式等新技术发展,对系统进行升级迭代。四是推动企业级管理升级,助力零售战略落地。五是支持邮储银行未来5至10年的持续发展。
通用计算一直走在IT技术变革的前列,开源成为构建数字世界的基石,已是业界共识。邮储银行选择基于通用计算平台加开源软件技术构建分布式基础IT能力,建设新一代分布式核心系统。
这次重构并不是单纯从技术上实现分布式,而是要奠定邮储未来创新发展的基础,首先要梳理企业内部流程。邮储银行新核心的建设路径采用业务和技术双轮驱动,一方面围绕银行战略,通过建模对业务进行重新梳理,建立模型资产库,对业务进行抽象,模块化,组件改造,达到乐高模式,按需快速构建。另一方面以分布式技术进行技术支撑。在技术层面,对建模的业务模型库,在分布式技术平台上进行实现,包括运维,全链路跟踪,分库分表数据存储,底层数据库采用国产开源数据库openGauss。
“我们邮储银行是国有大型银行,我们有使命和担当,我们要用一种国产的开源的数据库,推进基础软件的国产自主可控。”牛新庄在大会上说道,这个过程并不容易,项目团队进行了多轮论证。在加强分布式数据库本身的企业级能力等方面,邮储银行的本次实践积累了宝贵的经验。
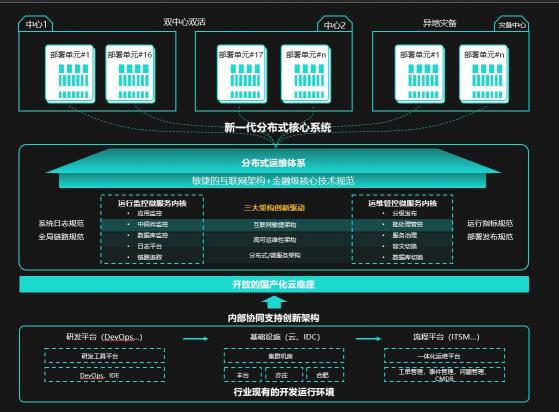
据悉,新核心系统设计为分布式架构、单元化部署,通过水平拆分方式承载业务。采用微服务、容器化、AI和DevOps等领先的IT技术,同时在底层数据资产通过多个分库分担不同业务单元压力,分解和稀释了系统对单个单元或分片数据库的性能等方面需求,避免单机性能瓶颈,支撑当前高并发的业务场景。每个标准部署单元拥有同样的软硬件结构,只是存储不同客户的业务数据。未来当客户增加时,只需要复制新的 “部署单元”,就可以简便、快速地进行系统资源的扩展,从而快速提升整体系统处理能力。
新核心系统整体上遵循平滑切换、有序上线的原则,2020年5月,进行基于鲲鹏硬件产品、openGauss数据库等软硬件原型验证,经过一年多的建设,邮储银行基于鲲鹏全栈打造的新一代分布式新核心系统陆续投产,2021年4月18日,整体技术平台上线,开始接入生产系统进行镜像验证,7月上线分布式运维系统,利用AI技术解决海量节点带来的运维复杂度。
邮储银行分布式新核心系统投产以来,效果显著,新核心系统整体性能提升了100%,全局路由查询能力提升了50%,插入/更新能力提升了10%。新核心系统将于2022年3月份全量投产,未来将支持邮储日均20亿笔的交易和创新业务的发展。“这充分地证明,国产数据库在性能上,我们毫不逊色的。”牛新庄在大会分享时说道。
为什么是openGauss
从投产的结果来看,基于通用计算平台加开源软件技术构建新核心这条路选对了,但是通用计算平台和开源软件有很多选择,这里依然有很多疑问,为什么在核心数据管理采用openGauss?而非历史更悠久的MySQL或PostgreSQL?openGauss开源时间不长,市场验证少,是什么打动了邮储银行?
在选型时,主要考虑产品与方案的技术领先性、生态成熟度、可参照商用性况、人才可获得性几个方面,而鲲鹏全栈生态完全满足其需求。
鲲鹏处理器具有多核高并发,结合欧拉(openEuler)操作系统和openGauss数据库等基础软件产品,充分释放全栈算力,为客户带来领先的极致性能。其次,鲲鹏计算产业生态蓬勃发展,已有3500多个合作伙伴,超1万个解决方案,覆盖金融,运营商,政府,制造,能源,交通等主流应用场景。在人才方面,21年已联合教育与72所高校合作,推出鲲鹏智能基座,推动进高校,进课堂。未来3年将有500所高校开展鲲鹏人才培养。而openGauss无论在x86还是鲲鹏上的性能对比MySQL和PostgreSQL均大幅领先,有高于其1倍多的性能优势,这得益于openGauss先进的內核根技术突破。在解决现有开源产品技术痛点的同时,不断创新。且在华为內部经过验证,openGauss开源之前,在华为內部的电信产品中已经应用了十几年,支撑了全球近百个运营商,几十亿用户的基础通信服务。海量用户长时间的打磨,不断促进openGauss的成熟。
更重要的是openGauss通过开源方式向业界贡献后,以其领先的內核技术和蓬勃、成熟的生态,迅速吸引了国內大量的企业加入社区,不断向社区回馈,使开源产品更加成熟。同时12家伙伴加入商用发行行列,为客户提供商用产品和专业服务。据悉,邮储银行作为openGauss社区理事会成员单位,承担着Committer角色,不但把openGauss应用到自身的核心系统中,同时积极向社区反馈问题,提出优化建议,促进openGauss更加成熟,贡献开源,发展开源。
回首邮储银行分布式新核心的建设之路,对邮储银行自身和业界意义重大。对邮储银行而言新核心不仅仅是一个领先的业务创新平台,更是一个未来发展的核心引擎;对业界来讲新核心实践更是一次金融核心系统技术变革的尝试,积累了宝贵的可借鉴的经验。同时也颠覆了业界对核心建设的认知:银行IT技术也可以是既稳定又技术领先的代表。鲁迅说过:“其实地上本没有路,走的人多了,也便成了路”,邮储银行作为利用通用计算+开源软件搭建核心系统的先行者,为后来者开拓了一条可行的创新路。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















