
近日,在美国休斯敦闭幕的第13届网络搜索与数据挖掘国际会议(WSDM 2020)上,华为云语音语义创新Lab带领来自华南理工大学、华中科技大学、江南大学、武汉大学学生组成的联合团队,摘得WSDM Cup 2020大赛“论文引用意图识别任务”金牌(Gold Medal)。
WSDM被誉为全球信息检索领域最有影响力也最权威的会议之一,会议关注社交网络上的搜索与数据挖掘,尤其关注搜索与数据挖掘模型、算法设计与分析、产业应用和提升准确性与效果的实验分析。今年已经是WSDM的第十三届会议。
本文将详细介绍本次获奖的解决方案。文章转载自华为云社区https://bbs.huaweicloud.com/blogs/149716
1、背景
几个世纪以来,社会技术进步的关键在于科学家之间坦诚的学术交流。新发现和新理论在已发表的文章中公开分发和讨论,有影响力的贡献则通常被研究界以引文的形式认可。然而,随着科研经费申请竞争日趋激烈,越来越多的人把学术研究当成一种资源争夺的手段,而不是单纯为了推动知识进步。部分期刊作者“被迫”在特定期刊中引用相关文章,以提高期刊的影响因子,而论文审稿人也只能增加期刊的引用次数或h指数。这些行为是对科学家和技术人员所要求的最高诚信的冒犯,如果放任这种情况发展,可能会破坏公众的信任并阻碍科学技术的未来发展。因此,本次WSDM Cup 2020赛题之一将重点放在识别作者的引文意图:要求参赛者开发一种系统,该系统可以识别学术文章中给定段落的引文意图并检索相关内容。
华为云语音语义创新Lab在自然语言处理领域有着全栈的技术积累,包括自然语言处理基础中的分词、句法解析,自然语言理解中的情感分析、文本分类、语义匹配,自然语言生成,对话机器人,知识图谱等领域。其中和本次比赛最相关的技术是语义匹配技术。Xiong团队通过对赛题任务进行分析,针对该问题制定了一种“整体召回+重排+集成”的方案,该方案以轻量化的文本相似度计算方法(如BM25等)对文章进行召回,然后基于深度学习的预训练语言模型BERT等进行重排,最后通过模型融合进行集成。
2、赛题介绍
本次比赛将提供一个论文库(约含80万篇论文),同时提供对论文的描述段落,来自论文中对同类研究的介绍。参赛选手需要为描述段落匹配三篇最相关的论文。
例子:
描述:
An efficient implementation based on BERT [1] and graph neural network (GNN) [2] is introduced.
相关论文:
[1] BERT: Pre-training of deep bidirectional transformers for language understanding.[2] Relational inductive biases, deep learning, and graph networks.
评测方案:
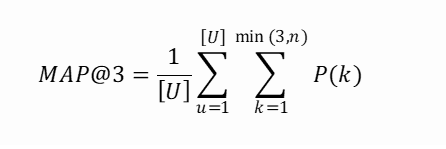
3、数据分析
本次赛题共给出80多万条候选论文,6万多条训练样本和3万多条本测试样本,候选论文包含paper_id,title,abstract,journal,keyword,year这六个字段的信息,训练样本包含description_id,paper_id,description_text这三个字段的信息,而测试数据则给出description_id和description_text两个字段,需要匹配出相应的paper_id。
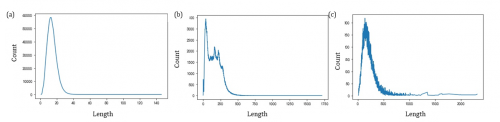
我们对数据中候选论文的title,abstract以及描述文本的长度做了一些统计分析,如图1所示,从图中我们可以看到文本长度都比较长,并且针对我们后续的单模型,我们将模型最大长度从300增加到512后,性能提升了大约1%。
图1 候选论文的Title(a),Abstract(b)以及描述文本(c)的长度分布
4、整体方案
我们方案的整体架构如图2所示,整体方案分为四个部分:数据处理,候选论文的召回,候选论文的重排以及模型融合。
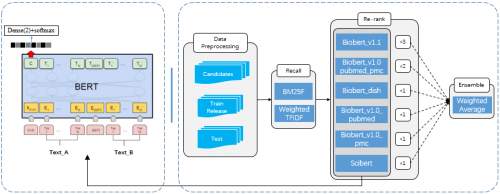
图2 整体方案架构(部分图引自[5])
4.1 数据处理
通过观察数据我们发现,在标题给出的描述语句中,有许多相同的描述文本,但是参考标记的位置却不同。也就是说,在同一篇文章中,不同的句子引用了不同的论文。为此,我们抽取句子中引用标记位置处的语句作为新的描述语句生成候选集。
如表1所示,我们选取描述中[[**##**]]之前的句子作为描述关键句。
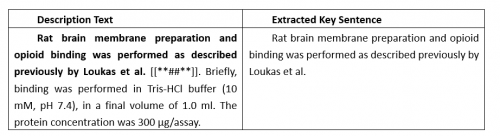
表1 描述关键句生成
4.2候选论文召回
如图3所示,我们运用BM25和TF-IDF来进行论文的召回,选取BM25召回的前80篇论文和TF-IDF召回的前20篇论文构成并集组成最终的召回论文。

图4 BioBERT结构图 (图引自[6])
4.4 模型融合
在模型融合的过程中,我们运用了6种共9个经过科学和生物医药语料库训练的预训练模型分别为:BioBERT_v1.1* 3, BioBERT_v1.0_PubMed_PMC * 2, BioBERT_v1.0_PubMed* 1,BioBERT_v1.0_PMC * 1, BioBERT_dish*1,SciBERT* 1。他们的单模型在该任务中的性能如表2所示。
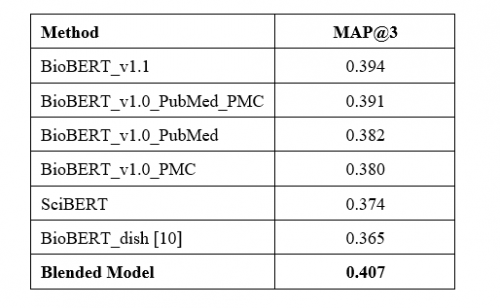
表2 单模型性能
然后我们对单模型输出的概率结果进行blending操作如图5所示,得到最后的模型结果,其比最好的单模型结果提升了1个百分点左右。
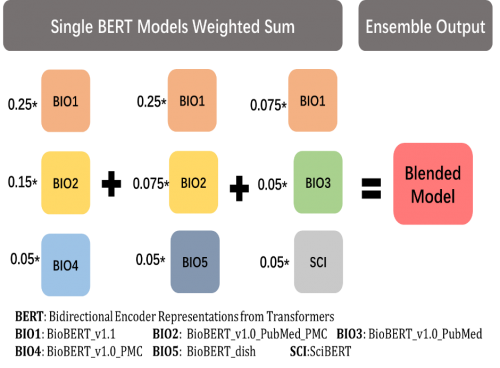
图5 模型融合
5、总结与展望
本文主要对比赛中所使用的关键技术进行了介绍,如数据处理,候选论文的召回与重排,模型融合等。在比赛中使用专有领域训练后的预训练模型较通用领域预训练模型效果有较大的提升。由于比赛时间的限制,许多方法还没来得及试验,比如在比赛中由于正负样本不平衡,导致模型训练结果不理想,可以合理的使用上采样或下采样来使样本达到相对平衡,提升模型训练效果。
参考文献
[1] Yang W, Zhang H, Lin J. Simple applications of BERT for ad hoc document
retrieval[J]. arXiv preprint arXiv:1903.10972, 2019.
[2] Gupta V, Chinnakotla M, Shrivastava M. Retrieve and re-rank: A simple and
effective IR approach to simple question answering over knowledge
graphs[C]//Proceedings of the First Workshop on Fact Extraction and
VERification (FEVER). 2018: 22-27.
[3] Peters M E, Neumann M, Iyyer M, et al. Deep contextualized word
representations[J]. arXiv preprint arXiv:1802.05365, 2018.
[4] Radford A, Wu J, Child R, et al. Language models are unsupervised multitask
learners[J]. OpenAI Blog, 2019, 1(8): 9.
[5] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. (2018)
BERT: Pre-training of Deep Bidirectional Transformers for Language
Understanding. arXiv preprint arXiv:1810.04805,.
[6] Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim,
Chan Ho So, Jaewoo Kang,(2019) BioBERT: a pre-trained biomedical language
representation model for biomedical text mining, Bioinformatics,
[7] Iz Beltagy, Kyle Lo, Arman Cohan. (2019) SciBERT: A Pretrained Language
Model for Scientific Text, arXiv preprint arXiv:1903.10676SciBERT: A
Pretrained Language Model for Scientific Text, arXiv preprint arXiv:1903.10676,
2019.
[8] Nogueira R, Cho K.(2019) Passage Re-ranking with BERT. arXiv preprint
arXiv:1901.04085.
[9] Alsentzer E, Murphy J R, Boag W, et al. Publicly available clinical BERT
embeddings[J]. arXiv preprint arXiv:1904.03323, 2019.
免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。





























