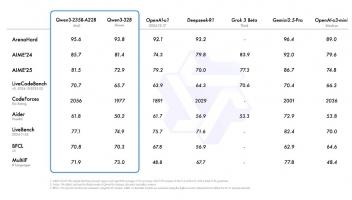
9月26日消息,楷登电子(美国 Cadence 公司)近日发布了用于加速人工智能系统级芯片开发的 Tensilica® AI 平台,包括针对不同的数据要求和终端侧 (on-device) AI 要求而优化的三个支持产品系列。
全面的 Cadence® Tensilica AI 平台涵盖低端、中端和高端市场,提供了可扩展、节能的设备端到边缘端人工智能处理功能,这是当今日益普遍的人工智能系统级芯片设计的关键。与业界领先的独立 Tensilica DSP 相比,新的配套 AI 神经网络引擎 (NNE) 每次推理的能耗降低了 80%,并提供超过 4 倍的 TOPS/W性能,而神经网络加速器 (NNA) 通过一站式解决方案提供旗舰级的 AI 性能和能效。
针对智能传感器、物联网 (IoT) 音频、手机视觉/语音 AI、物联网视觉和高级驾驶辅助系统 (ADAS) 应用,Tensilica AI 平台通过一个通用软件平台提供最佳的功耗、性能和面积 (PPA) 以及可扩展性。Tensilica AI 平台产品系列依托大获成功的 Tensilica DSP,Tensilica DSP 针对特定的应用,已经在消费、移动、汽车和工业市场的领先人工智能系统级芯片中投入量产,包括:
AI Base:包括用于音频/语音的热门 Tensilica HiFi DSP、Vision DSP 以及用于雷达/激光雷达和通信的 ConnX DSP,与 AI 指令集架构 (ISA) 扩展结合使用。
AI Boost:增加了一个配套的 NNE,最初是 Tensilica NNE 110 AI 引擎,可从 64 GOPS 扩展到 256 GOPS,并提供并发信号处理和高效推理。
AI Max:包括 Tensilica NNA 1xx AI 加速器系列——目前包括 Tensilica NNA 110 加速器和 NNA 120、NNA 140 以及 NNA 180 多核加速器选项——该系列集成了 AI Base 和 AI Boost 技术。多核 NNA 加速器可以扩展到 32 TOPS,而未来的 NNA 产品的目标是扩展到上百 TOPS。所有的 NNE 和 NNA 产品都包括用于提高性能的随机稀疏计算、旨在减少内存带宽的运行时张量压缩,以及可以减少模型大小的修剪和聚类功能。该全面的通用人工智能软件面向所有目标应用,简化了产品开发,并能随着设计要求的变化而灵活轻松的迁移。该软件包含 Tensilica Neural Network Compiler,该产品支持以下工业标准的框架:TensorFlow、ONNX、PyTorch、Caffe2、TensorFlowLite 和 MXNet,用于自动生成端到端的代码;Android Neural Network Compiler;TFLite Delegates,用于实时执行;以及 TensorFlowLiteMicro,用于微控制器级设备。
NNE 110 AI 引擎和 NNA 1xx AI 加速器系列支持 Cadence 的智能系统设计 (Intelligent System Design™) 战略,该战略旨在为系统级芯片的卓越设计提供普适智能支持,预计将在 2021 年第四季度全面上市。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )