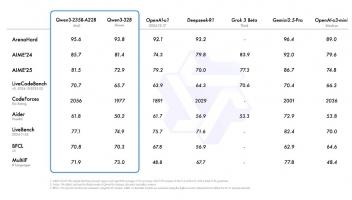
7月6日,昇腾人工智能产业高峰论坛在上海举办。会上,中国科学院院士、清华大学计算机系教授、清华大学人工智能研究院名誉院长张钹发表演讲。

以下是张钹演讲全文:
各位专家、各位嘉宾、大家好!非常高兴被聘请为昇腾荣誉顾问,这可能是对人工智能工作者的一种鼓励,我觉得人工智能工作者是需要鼓励的,因为人工智能是在闯无人区,人工智能取得的每一个进步都是非常艰难的。
首先,我想谈一个问题,怎么样估计ChatGPT的成就?目前有两种说法,一种说法是ChatGPT是通用人工智能,还有一种说法它不是通用人工智能,哪个对呢?我的观点是哪个都不对。怎么样估计ChatGPT的成果呢?我认为最恰当的估计是向通用人工智能迈出一步。按照微软的说法是通用人工智能的火花,我赞成这种观点。
为什么呢?首先ChatGPT具有通用人工智能的以下两个特征,第一个特征是在对话和聊天这个领域,它达到了人工智能的目标,或者说达到了行为主义主张的人工智能的目标。行为主义人工智能是人工智能的主流,背后的哲学是唯物主义、实用主义。它追求的人工智能目标是什么?使得机器的行为跟人类的行为相似,为什么说ChatGPT达到了这个目标呢?因为我们跟ChatGPT对话的时候,和与人类的对话很相近,因此它满足第一个通用人工智能的特征。
第二个特征,ChatGPT是开领域、多任务的,在对话这个问题里跟领域无关,这是一个重大的突破。大家知道人工智能经历过第一代知识驱动,第二代数据驱动,都只能在限定领域里面完成单个任务。ChatGPT变成开领域,走向通用。在通用人工智能最重要的两个特征上达到要求,即一个接近人类水平,一个跟领域无关。所以,我们可以说它向通用人工智能迈出一步。因为它只是在对话,或者讲得宽一点,是在语言处理这个领域里面达到这个目标,所以我们还不能把它称作通用人工智能。因为在别的人工智能领域里面,它是不是能通用呢?现在还说不清楚,所以我觉得这样的估计是非常恰当的。我们只有在这样的估计下,才能讨论下面的问题。
首先一个问题,ChatGPT为什么能够达到现在这样的水平,甚至很多地方使大家感到非常惊奇?主要是由于人工智能经过六七十年的努力,在三个问题上实现了突破,或者说是三个关键科技问题的突破。
第一个科技问题,基于词嵌入的文本语意表示。
第二个科技问题,是大家非常熟悉的转换器,就是基于注意机制的转换器,也就是大模型,我们现在说的大模型就是大转换器。
第三个科技问题,就是基于“预测下一个词”的自监督学习,我们应该说ChatGPT是经过人工智能领域里或者多个领域里大量的科学家和工程师,经过六七十年共同努力的结果,因为经过六七十年这三个问题才得到突破。这三个科技问题的突破,使得机器在处理文本上起到了本质的变化,过去我们在处理文本的时候,我们往往把它称作处理数据,到现在为止,大家还是用的这个词,但是这个词在ChatGPT里不成立。
因为ChatGPT是在我们找到了文本语意表示这个条件下再处理文本,所以它处理的不是文本的形式,不是把文本当成数据来处理,而是把文本当成知识来处理。
所以,ChatGPT成功并不是仅仅归功于三个要素,也就是数据、算力和算法。我觉得应该强调四个要素,分别是知识、数据、算法和算力。也就是说,我们有了三个关键问题的突破,就使得我们能够从大量的文本,所谓“数据”,从大量的数据中获取知识,只有出现这个转变才有现在的ChatGPT,如果我们还是停留在那个认识上肯定是错的。
这个突破可能带来三件事情的发生,且是不可阻挡的:
第一件事就是必然带来科技的革命,首先会带来人工智能本身的革命。大家知道人工智能发展到ChatGPT以前,我们不能说它是一门科学,为什么呢?它没有理论,人工智能为什么理论建立不起来?非常重要的原因是,我们在第一代人工智能做的知识驱动也好,第二代人工智能做的数据驱动也好,我们都是在限定领域中完成单个任务。你在单领域单任务里面不可能建立一个通用的理论。ChatGPT扫除了这个障碍,至少在自然语言处理上扫除了这个障碍,因为它跟领域无关。一旦跟领域脱钩了,你才有可能建立起来它的通用理论。
所以,现在去建立人工智能理论是有可能的,在ChatGPT没出现以前,这种可能性不存在。因此,这个问题对我们来讲是一个激励。什么是突破口呢?突破口就是ChatGPT本身,如果我们没有把ChatGPT内部的工作原理搞清楚,我们就找不到进入人工智能理论的钥匙。
大家想一想ChatGPT里面很多现象,我们说不清楚,比如,一方面它能够生成一些非常出人意料、非常好的结果。它同时又会出现幻觉,什么是幻觉呢?就是胡说八道。所以,为什么会出现这个现象呢?目前还不清楚,所以第一个必然会迎来的科技革命,就是AI本身的革命。
第二个事情,大家讨论得非常多,就是产业的变革。首先是人工智能产业本身的变革,大家知道人工智能产业的发展跟信息技术与产业的发展是非常不一样的,信息科技与产业的发展,我们可以用4个字来形容——“高速持续”,但是人工智能科技与产业的发展却是“缓慢曲折”,什么原因呢?一个最重要的原因就是信息科技从一开始,理论就建立起来了,计算机的理论是1936年建立的,通讯理论是1948年建立的,在它的理论指导下,它的技术和产业发展都非常顺利。
而人工智能至今只有算法和模型,且这些算法和模型都是领域限定和任务限定的,所以你开发出来的人工智能的硬件或软件全是专用的,跟信息产业完全不同,信息产业的所有硬件和软件通常是通用的,市场非常之大。而人工智能产业的硬件或软件通常是专用的,都是跟领域紧密结合的,人工智能产业不跟领域结合根本不可能有这个产业。拿计算机来讲,它的硬件和软件不需要跟领域结合,生产出来的计算机什么地方都能用。
但是有了ChatGPT之后,人工智能有可能建立一个跟领域一定程度上无关的模型和算法,只有这个算法和模型摆脱了领域的限制,你将来生产出来的硬件和软件才会是通用的,或者是一定范围里通用的,你才有很大的市场。这就是今后人工智能产业变革的一个方向。
第三个事情,人工智能治理。ChatGPT大家看正面得比较多,其实反面的东西也很多,因为它使用的学习方法叫“预测下一个词”,这种学习范式,必然带来两个大问题:
首先,它的结果不确定,其次,受提示词的影响极大,这就造成Chat GPT输出有三个不可避免的缺点:
第一个缺点,错误是必然的。所以我们说的那个胡说八道是必然的。
第二个缺点,它的输出受输入的影响很大,受提示词的影响很大,所以它的输出多样化,问同样的问题改变“提示词”就会得到完全不同的结果。
第三个缺点,它不知道自己错了,错了也改不了,必须依靠AI对齐等等。我问ChatGPT清华大学校歌的歌词是什么?它自己编了一套。我说不对,清华大学校歌不是你说那样,应该是“西山苍苍,东海茫茫,...”,我把校歌歌词输给它,它马上回复说对不起我说错了,清华大学歌词应该是这个。我退出来再进去,问它清华大学的校歌是什么?它又自己编了一套,说明它不知道自己错了,告诉了它的错误它也改不过来。
想一想,这些情况说明ChatGPT的输出往往不一定符合我们的要求,符合我们的道德、伦理、政治的标准。所以ChatGPT出现以后,人工智能的治理是不可避免的,我认为这三个趋势一定是这样的。
我们怎么办呢?我们主张发展第三代人工智能,发展第三代人工智能包含三个内容,一个内容就是要建立可解释鲁棒的人工智能理论。ChatGPT出现以后建立这个理论才成为可能,过去实际上是很难建立这个理论。第二个内容,发展安全、可信、可控、可靠、可拓展的人工智能技术,只有建立了这个理论之后,我们才有可能得到一个安全的人工智能技术。换句话说,现在的人工智能技术是不安全的,不可靠的,也是不可信的。特别是利用大数据的机器学习,结果一定是这样的。最后才能推动创新应用和产业发展。我相信通过全国的规划与部署,通过产学研的结合,这个目标一定会达到。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )