标题:Meta突破技术界限:自回归模型翻新图像生成,AI能生成2048×2048分辨率惊人图像
随着科技的进步,人工智能(AI)正在逐步改变我们的生活。近日,Meta AI创新推出Token-Shuffle,这一技术突破旨在解决自回归模型在生成高分辨率图像方面的扩展难题。Token-Shuffle通过识别多模态大语言模型中的视觉词汇冗余,提出了一种创新策略,直击计算成本问题,让自回归模型能够高效处理最高2048×2048分辨率的图像。
自回归模型是一种用于时间序列分析的统计方法,主要用于预测数据序列中的未来值。该模型的核心思想是当前的值与过去的值之间存在线性关系,因此可以用变量自身的历史数据来预测当前或未来的值。近年来,自回归模型在图像合成方面大放异彩,然而在面对高分辨率图像时,AR 模型遭遇瓶颈。
Token-Shuffle的推出,为这一瓶颈问题提供了有效的解决方案。该方法通过将空间上相邻的视觉token沿通道维度合并,并在推理后再恢复原始空间结构,大幅降低了计算成本。这种token融合机制不仅让自回归模型能够高效处理高分辨率图像,还无需改动Transformer架构,也无需额外预训练编码器,操作简单且兼容性强。
具体而言,Token-Shuffle包含token-shuffle和token-unshuffle两个步骤。输入准备阶段,空间相邻的token通过MLP(多层感知机)压缩为单个token,减少token数量。以窗口大小s为例,token数量可减少s²分之一,显著降低Transformer的计算量(FLOPs)。此外,该方法还引入了针对自回归生成的classifier-free guidance(CFG)调度器,动态调整引导强度,优化文本-图像对齐效果。
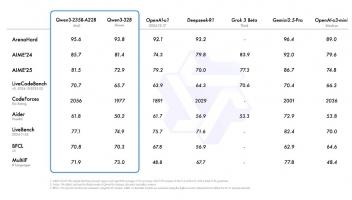
实验结果表明,Token-Shuffle在GenAI-Bench和GenEval两大基准测试中展现了强大实力。基于2.7B参数的LLAMA模型,Token-Shuffle在“困难”提示下取得VQAScore 0.77,超越了其他AR模型如LlamaGen和扩散模型LDM。而在GenEval中,其综合得分也达到了0.62,为AR模型树立了新标杆。用户评估也显示,尽管在逻辑一致性上略逊于扩散模型,但Token-Shuffle在文本对齐、图像质量上优于LlamaGen和Lumina-mGPT。
值得注意的是,Token-Shuffle不仅在技术上有所突破,而且为未来的发展提供了广阔的空间。首先,随着算力资源的不断提升,高分辨率图像生成将成为可能。这意味着我们可以获得更加精细、更加真实的图像,这对于医疗、科研、艺术等领域具有重要意义。其次,Token-Shuffle方法的兼容性强,易于与其他AI技术结合使用,进一步拓展其在各个领域的应用范围。最后,Token-Shuffle的提出也反映了Meta AI对于人工智能研究的重视和投入,这无疑将推动AI技术的发展,为人类生活带来更多便利。
总的来说,Meta AI的Token-Shuffle为自回归模型在图像生成领域打开了新的可能。这一突破性的技术不仅提高了生成图像的质量和效率,也为未来的研究提供了新的方向。我们期待看到更多像Token-Shuffle这样的技术出现,推动人工智能的发展,为人类社会带来更多福音。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )