
近日,虎博科技满怀诚意地发布TigerBot V2,涉及基座模型、chat模型、产品升级、 TigerBot-API升级等多个方面的更新。此次,虎博科技将同步共享TigerBot发布的具体内容和训练过程中的一些科学和工程的探索结果,与大模型开发者们一同推动AIGC的繁荣。
如想率先体验虎博科技TigerBot的新版本,可通过以下地址前往:
TigerBot demo 在线体验:https://tigerbot.com/chat
Github 项目: https://github.com/Tigerye/TigerBot
更新一:基座模型经评测已超部分主流开源模型近30%
虎博科技的TigerBot-7b-base-v2(基座模型)在1.5TB多语言数据上充分训练,千卡耗时一个月,投入算力成本约300万,在OpenAI采用的公开NLP 7项任务评测中,超过同等LLaMA、Bloom等主流开源模型达15%-30%。虎博科技团队认为,TigerBot的base-v2是业内同等大小模型里能力最强的base model之一,适合各领域开发者以此为基础继续预训练或者监督微调。
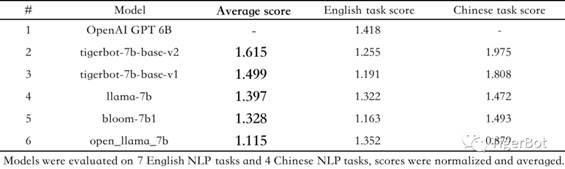
图1: 虎博科技TigerBot-7b-base-v2在public NLP 7 tasks evaluation performance

图2: 虎博科技TigerBot-7b-base-v2预训练数据分布
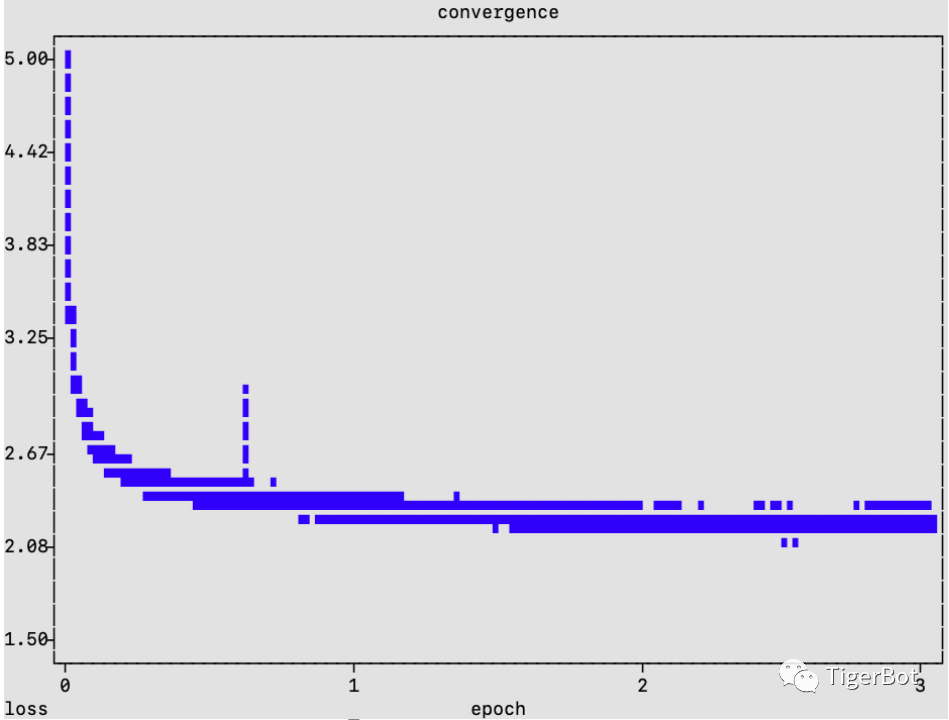
图3: 虎博科技TigerBot-7b-base-v2预训练loss收敛曲线
更新二:chat模型经9项公开语料测评,效果提升 9.3%
使用虎博科技TigerBot-7b-base-v2 经过有监督微调的chat model,在2000万(20G) 高质量清洗和配比的微调指令数据集上充分训练,在9项公开语料next-token prediction accuracy测评上优于TigerBot-7b-sft-v1版本9.3%,loss drop by 35%。虎博科技团队认为,TigerBot-7b-sft-v2是业内同等大小模型里能力最强的chat model之一,适合各领域应用开发者以此为基础开发问答、摘要、生成等任务的应用。

图4: 虎博科技TigerBot-7b-sft-v2在public NLP 9 tasks evaluation performance
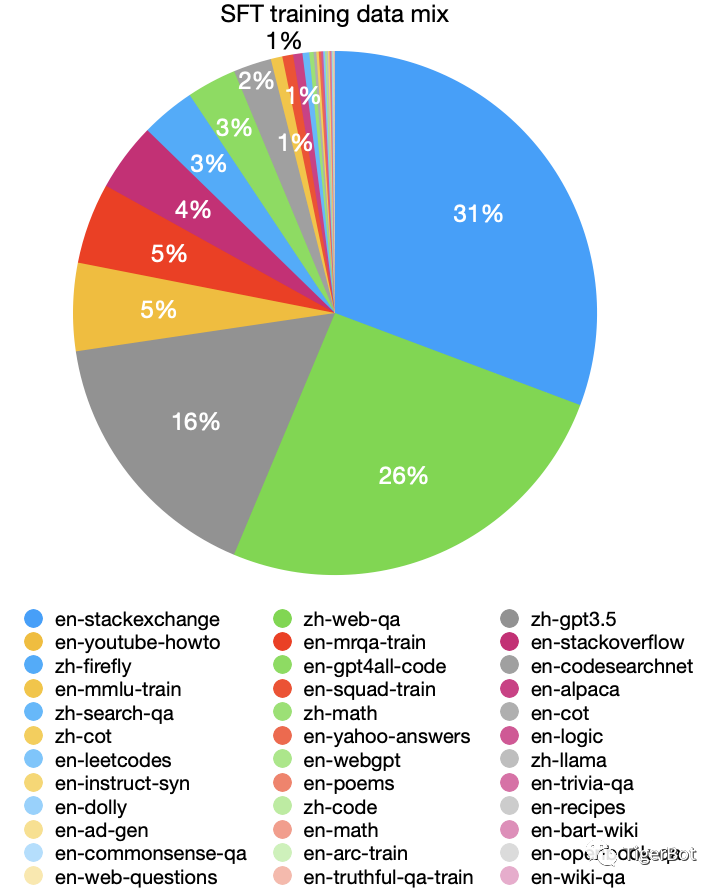
图5:虎博科技TigerBot-7b-sft-v2训练数据分布
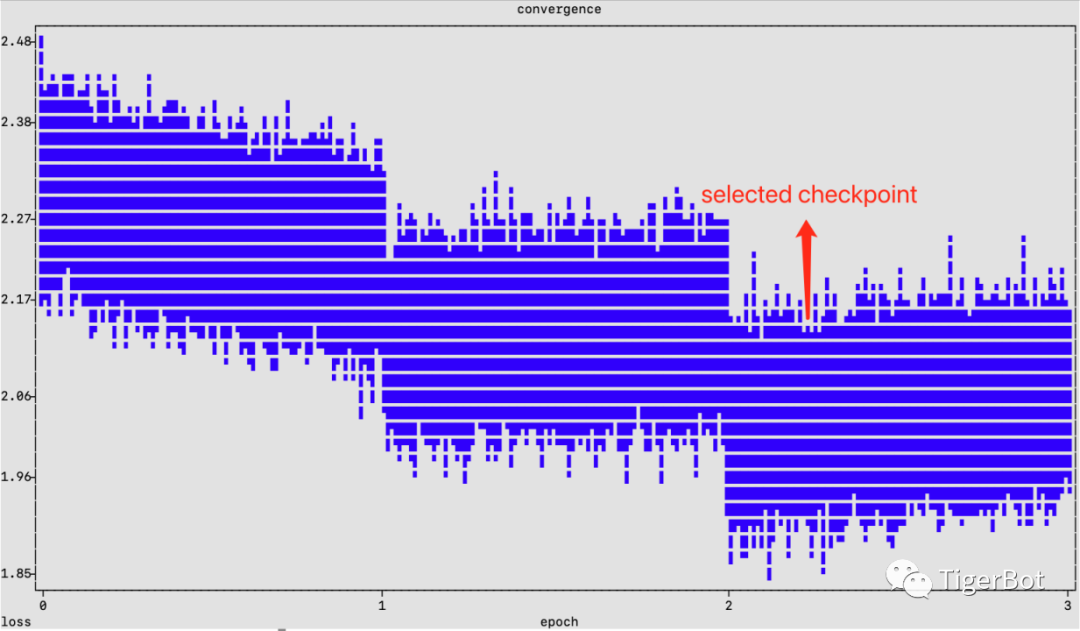
图6: 虎博科技TigerBot-7b-sft-v2训练loss收敛曲线
TigerBot-7b-sft-v2的chat样例如下所示:
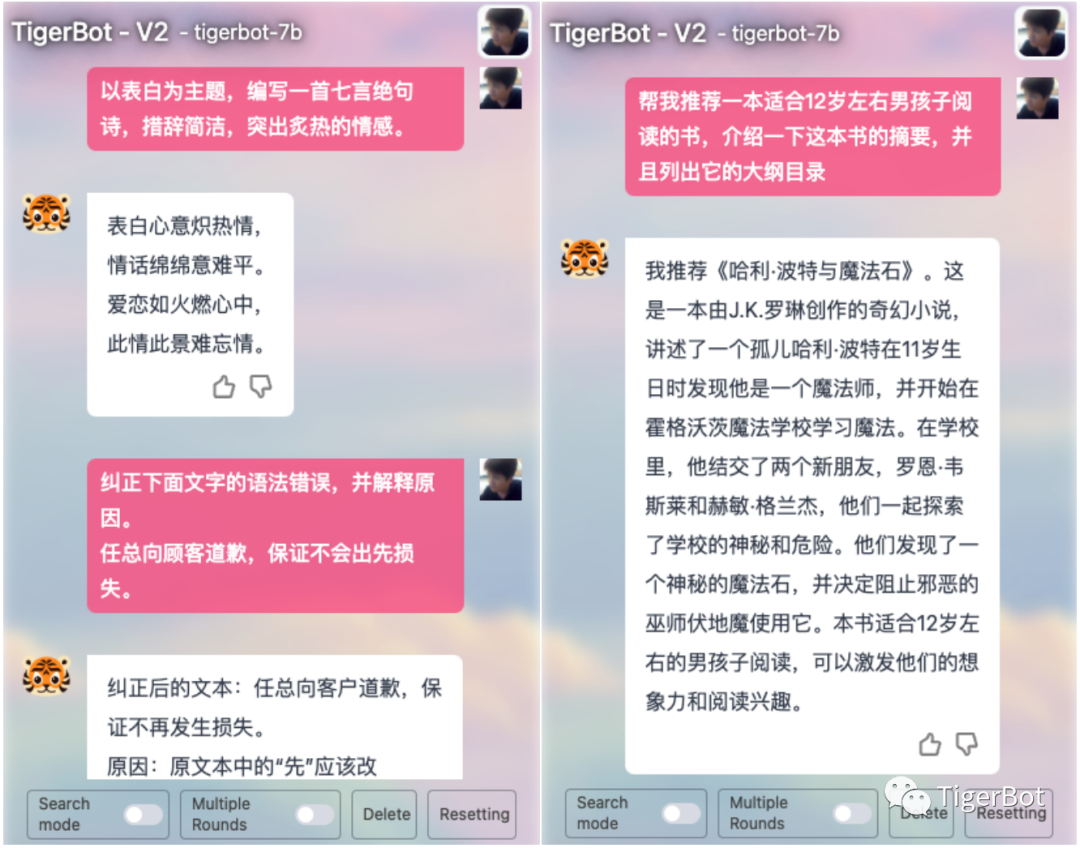


图7: 虎博科技TigerBot chat展示
更新三:产品升级——搜索模式和流式生成提升体验感
产品方面,因新版开启了搜索模式和流式生成,使用虎博科技的TigerBot产品也有了新的体验。虎博科技结合了互联网搜索和工具(如天气,股价,计算器等),打开了LLM+Search的应用场景,适合有实时信息查询需求的应用。同时开放的chat-api也支持搜索和流式模式的开关,如下图所示:
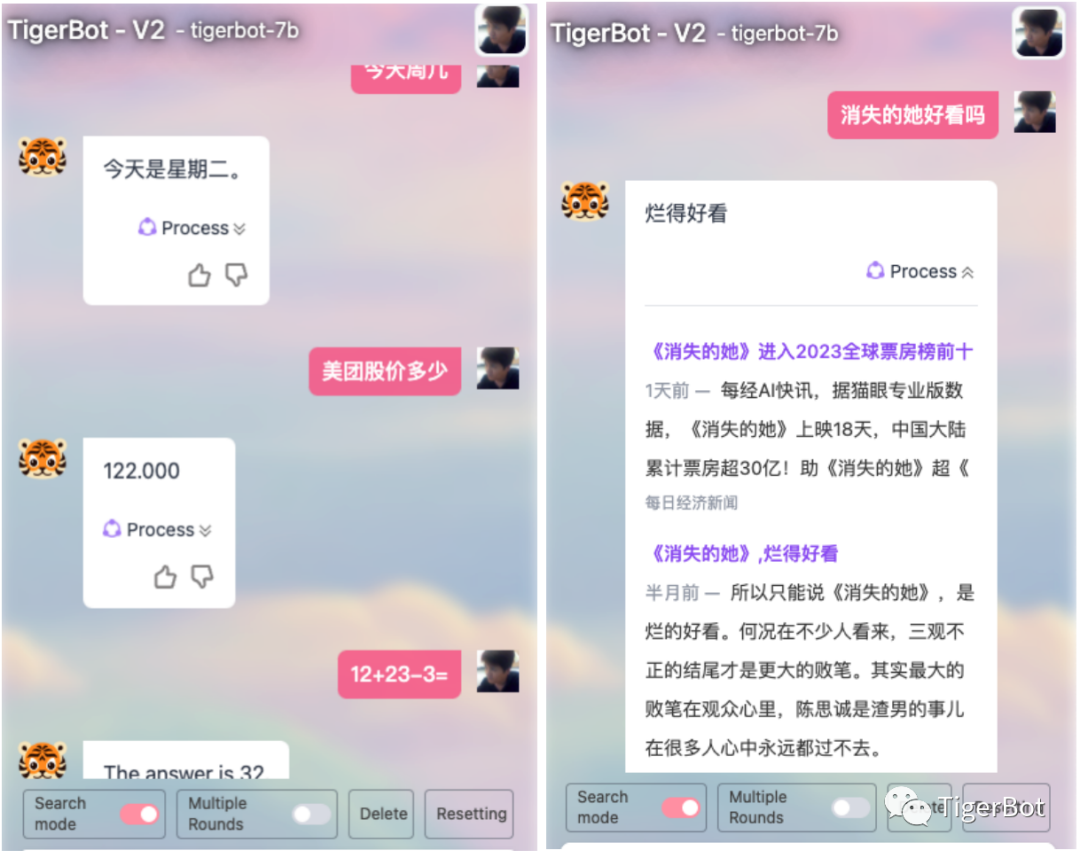
图8: 虎博科技TigerBot搜索模式页面示例
更新四:TigerBot-API升级,更多调用选择
虎博科技全面升级TigerBot-API,让使用者有了更多工具选择。虎博科技开放出LLM应用开发常用的工具,通过简单的API调用即可快速实现相关应用。API包括LLM下的chat, plugin, finetune, Text下的embedding, summarization, pdf2text, Visio下的text2image。API使用示例如下展示:

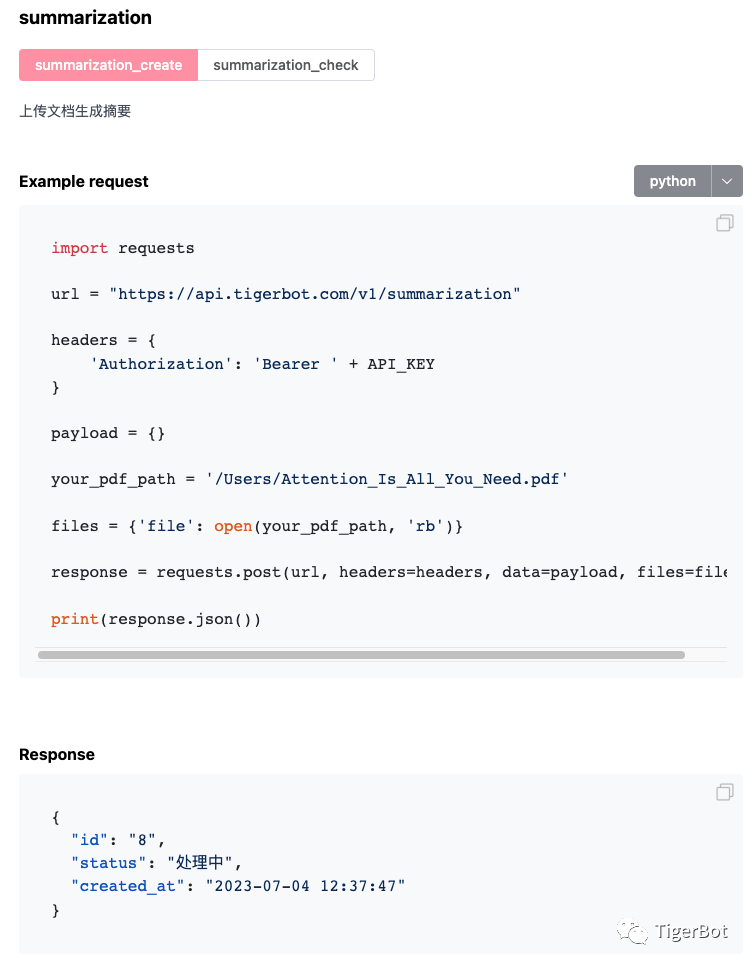
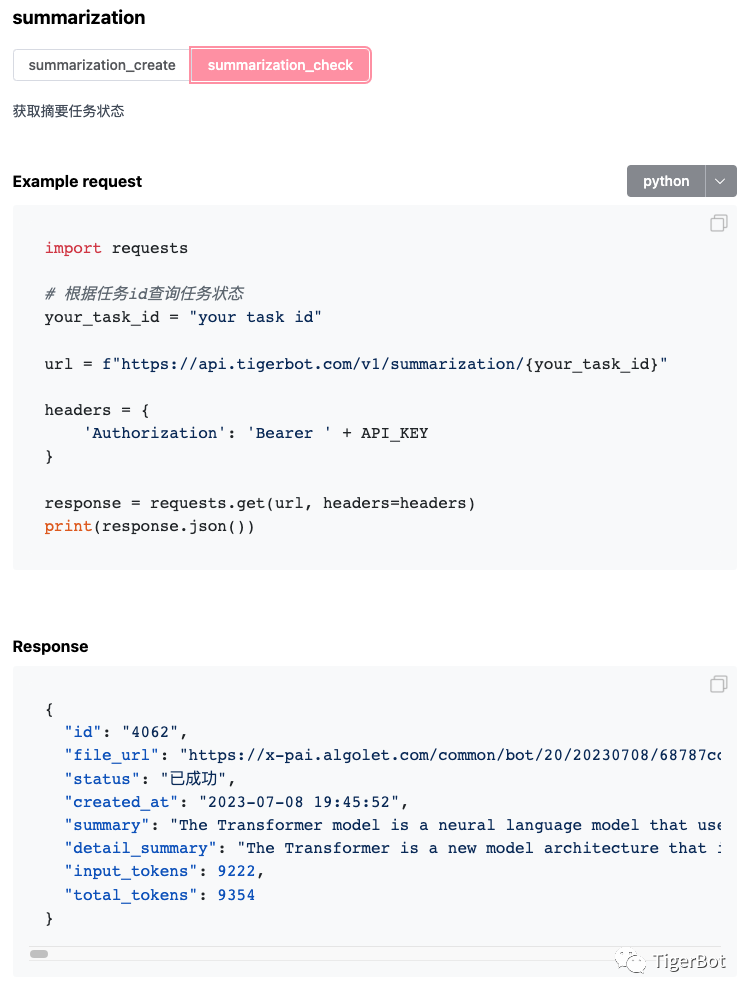
图9: 虎博科技TigerBot-API示例展示
TigerBot V2训练中的科学与工程探索
1. data quality or data volume ?
虎博科技创始人陈烨始终坚信数据的质量比数据的数量更重要,尤其是中文网络数据,TigerBot模型是在v1基础上继续预训练。虎博科技团队通过实验发现,模型本身有很强的学习和记忆能力,少到数十条低质量的数据就会让模型学到,导致不理想的回答风格。这里的低质量数据包括:网络口语词、社区论坛等的jargon、敏感和有害的内容(harmness)、广告类、格式不规范的内容。虎博科技团队通过规则和模型过滤掉~10%的低质量数据。其中针对敏感、涉黄、不符合主流价值观的内容,虎博团队选择用三个SOTA内容审核模型ensemble来过滤。
虎博科技团队采用以下步骤和算法清洗数据,以在O(n^2)的复杂度下获得高质量数据:
(1)先用规则去掉杂乱数据,例如instruction全是标点符号或者数字的,
(2)然后使用exact string match去重,
(3)再用sequence simhash + longest common substring去重,
(4)去重后利用SOTA审核模型去掉谩骂色情涉政的数据。
2. more epoch or more data ?
在高质量数据的基础上,模型的学习能力使得1-2epoch就能概率上学到数据中的知识和指令,所以虎博科技团队把有限的算力让模型去学习更多更丰富的知识和任务类型。在虎博科技团队的大部分实验中,模型的training loss在一个epoch后就收敛到最终的水平,eval loss会在2-3个epoch后增长即overfitting。这个观察也在bloom最初的预训练中得到印证,bigscience团队也是预训练了一个epoch后拿到模型。
3. eval loss or more data ?
在public NLP data上的自动评测是快速实验的基础,但自动评测多数是contextual QA task,即有上下文的情况下,评测模型的总结抽取等能力,和最终用户体感是有差异的。所以虎博科技团队首先在7项(预训练)和9项(监督微调)的public NLP benchmark上自动评测,以保证模型的综合能力(知识深度),然后从自动评测最高的三个模型中选择看过最多训练数据的模型(知识广度)。
4. important hyperparameters
虎博科技团队通过大量实验,发现重要的训练参数包括:learning rate (LR), (global) batch size, adam regularizers (alpha, beta)。最优的参数没有理论结果,也是数据和基座模型的函数。虎博科技团队先用较小的training/eval dataset上(e.g., 1% random sample),快速geometric search找到超参的范围;然后在全集training/eval dataset上geometric search到最佳超参。百亿量级的模型的监督微调在综合任务数据集上的best-practice global batch是512-2048,LR是1e-5 - 2e-5,warmup fixed LR;而千亿参数模型训练在2epoch之后会有loss explosion现象,所以虎博团队配合adam regularizer (beta2=0.95), 和warmup cosine LR schedule。
5. self-evoluation
虎博科技团队在预训练数据中混合入10%的监督微调数据,用非监督的格式。背后的直觉是预训练让模型专注基础知识p(t_n | t_n-1…),监督学习让模型专注指令完成p(response | instruction)。在sft的训练过程中,大部分的gradient会指向完成指令的方向,因为数据中的基础知识已经在预训练中学习过。这就是虎博科技团队让模型自我进化的思想(self-evoluation),这和人类循序渐进的学习知识一个原理;比如,NLP的学生总是先学好各种概率分布,然后再学习在各种任务数据中的应用,打好基础,事半功倍。
6. generation configs
在测评和上线模型的过程中,虎博科技团队发现是否使用解码cache (config.json, generation_config.json in model checkpoint folder) 对生成结果的一致性和性能有影响(输入输出token数分别为1024和100的情况下,使用cache的模型qps值约是不使用的7.7倍)。
虎博的模型基于decoder架构,可以缓存生成过程中每个attention计算使用的key/value投影结果,只增量计算每个新token与历史token的attention,从而将生成每个token时的softmax计算复杂度由O(n*n)降低为O(n*1)。但是否使用cache,会导致是否有额外的mask value参与softmax计算,因此在不同的硬件环境和不同计算精度下,cache可能会导致生成结果的微小差异。虎博科技团队在自动评测中确定use_cache=true or false,测评结果一致,因此chat web和api都设置为use_cache=true,以保证响应最快的用户体验。
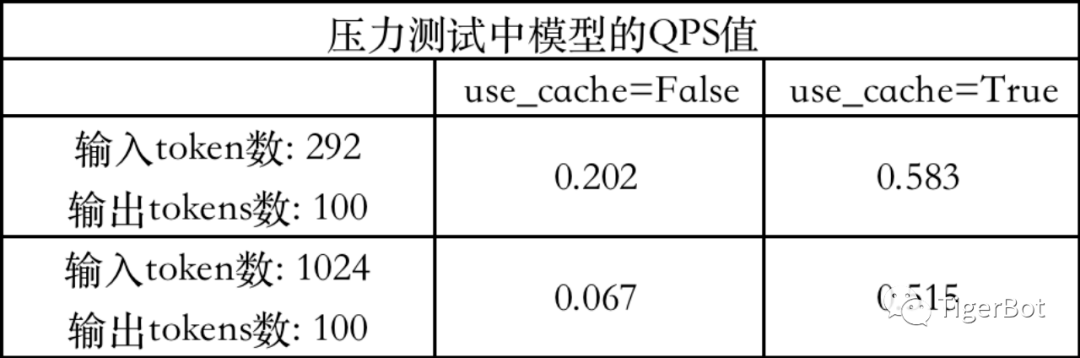
图10: use_cache vs. response time
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















