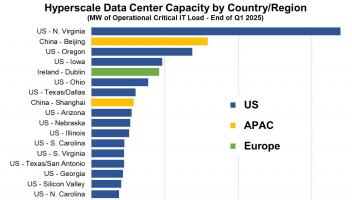
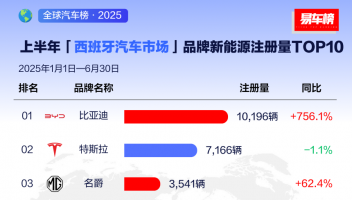
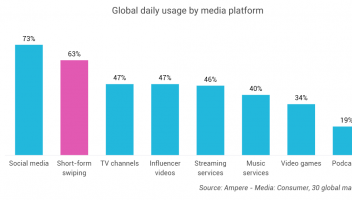
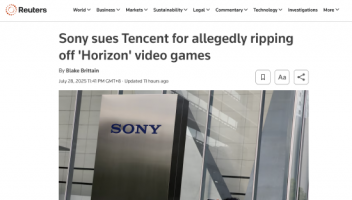
12月21日消息, 近期,AI基准测试MLPerf公布了最新一期的训练测试榜单,成为行业内关注的焦点。
IPU提供商Graphcore此次向MLPerf提交了IPU-POD16、IPU-POD64、IPU-POD128和IPU-POD256四种系统配置进行训练测试,并获得最新测试结果。在ResNet-50模型、自然语言处理(NLP)模型BERT的训练性能方面均有大幅提升。ResNet-50模型训练性能甚至超越NVIDIA DGX A100。
Graphcore专注于适用AI的IPU研发,旗下拥有IPU硬件和Poplar软件两项主要业务,通过输出“软硬一体解决方案”来服务机器智能需求。企查查信息显示,Graphcore自2016年成立以来已获得超过7.1亿美元投资。
和自己比:ResNet-50模型训练性能提升24% BERT模型训练性能提升5%
Graphcore提交给MLPerf的IPU-POD16、IPU-POD64、IPU-POD128和IPU-POD256系统均由不同数量的IPU-M2000、双CPU服务器构成。
IPU-POD16就是由4个1U的IPU-M2000构成,配有一台双CPU服务器,可提供4 petaFLOPS的AI算力。
其中,IPU-M2000是一款即插即用的机器智能刀片式计算单元,由Graphcore的7纳米Colossus第二代GC200 IPU提供动力,并由Poplar软件栈提供支持。
今年7月,Graphcore曾首次向MLPerf提交了IPU-POD16、IPU-POD64的训练测试。这次Graphcore同样有提交IPU-POD16、IPU-POD64进行测试,这两项在硬件方面并未有变化。
最新测试结果显示,与首次提交的MLPerf训练结果相比,对于ResNet-50模型,Graphcore这次在IPU-POD16上实现24%的性能提升,在IPU-POD64上实现了41%的性能提升;对于模型BERT来说,在IPU-POD16上实现了5%的性能提升,在IPU-POD64上实现了12%的性能提升。
Graphcore大中华区总裁兼全球首席营收官卢涛表示,这些性能提升是自Graphcore首次提交以来仅通过软件优化就实现的。MLPerf测试结果表明Graphcore的IPU系统更加强大、高效,软件也更成熟。
Graphcore大中华区总裁兼全球首席营收官卢涛
和同行比:ResNet-50模型训练 IPU-POD16性能超NVIDIA DGX A100
最新的MLPerf测试结果还对比了Graphcore与NVIDIA的产品性能。
通常而言,ResNet-50模型主要用于计算机视觉领域,NVIDIA GPU在ResNet-50模型上的测试结果长期处于领先地位。
不过,最新的MLPerf测试结果显示Graphcore的IPU-POD16在ResNet-50模型训练方面的表现优于NVIDIA的DGX A100。在DGX A100上训练ResNet-50需要29.1分钟,而IPU-POD16仅耗时28.3分钟。
DGX A100是NVIDIA去年5月发布的旗舰产品,DGX A100使用两颗AMD霄龙7742处理器,主打适用于所有AI工作负载。
对于Graphcore产品在ResNet-50模型测试上取得的成绩,卢涛表示:“ResNet是一个2016年的模型,已经在GPU上优化了5年。我们通过两次的MLPerf测试,就能够在这个GPU最主流的模型上超过GPU,这是非常自豪的一件事。而且我们后面还有进一步的提升空间。”
值得注意的是,Graphcore这一次MLPerf测试跟上一次相比最大的不同是首次提交了IPU-POD128和IPU-POD256大规模系统集群的测试。IPU-POD128和IPU-POD256也取得了很好的成绩。
从ResNet-50模型在不同机器集群上的训练性能来看,在IPU-POD16上的训练时间是28.33分钟,随着系统的增大,训练时间逐次递减。在IPU-POD64上,只需要8.5分钟;在IPU-POD128上训练的时间为5.67分钟;在IPU-POD256上,为3.79分钟。
对于NLP模型BERT,Graphcore在开放和封闭类别分别提交了IPU-POD16、IPU-POD64和IPU-POD128的结果,在新的IPU-POD128上的训练时间为5.78分钟。
谈及此次Graphcore提交系统测试性能整体都有提升的原因,卢涛向TechWeb表示,这一次提交了大规模集群,其背后是GCL(Graphcore Communication Library)通信库的基本完备,能够支撑搭建集群,这是Graphcore在产品和技术上迈进的重要一步。同时在产品细节上Graphcore团队也做了很多优化,如编译器优化、框架层面优化、算法模型优化、还有IPU跟CPU之间的通信优化等等。
卢涛介绍,在MLPerf原始数据中,每家制造商系统相关的主机CPU数量都十分惊人,而Graphcore的主机CPU与IPU的比率始终是最低的。以BERT-Large模型为例,IPU-POD64只需要一个双CPU的主机服务器。ResNet-50需要更多的主机处理器来支持图像预处理,Graphcore为每个IPU-POD64指定了四个双核服务器。1比8的比例仍然低于其他所有MLPerf参与者。能实现主机CPU与IPU的低比率是因为Graphcore的IPU仅使用主机服务器进行数据移动,无需主机服务器在运行时分派代码。因此,IPU系统需要的主机服务器更少,从而实现了更灵活、更高效的横向扩展系统。
在GPT2、ViT、EfficientNet等新模型上表现如何?
如果说ResNet-50、BERT等都是到2019年为止比较主流的模型。那么,近2年陆续涌现的GPT2、EfficientNet、ViT等新模型也越来越受到行业关注,比如,在AI领域,ViT已经成为学界和工业界用Transformer来做计算机视觉的一个比较典型的算法模型。
尽管没有在MLPerf中测试,Graphcore中国工程总负责人、AI算法科学家金琛展示了Graphcore产品在GPT2、EfficientNet、ViT等新模型中表现。
以EfficientNet-B4为例,在IPU-POD16上的训练需要20.7个小时,IPU-POD256则只需要1.8个小时,性能远优于DGX A100官方提供的数据。
Graphcore中国工程总负责人、AI算法科学家金琛
据介绍,目前Graphcore产品已经在金融、保险、天气预测、科学计算等领域落地,卢涛称,在金融领域案例中,IPU能够比GPU快10倍。在保险算法模型方面的案例中,IPU的应用比GPU快5倍。天气预测方面,在欧洲中期天气预报中心的模型上,IPU比CPU快50倍、比GPU快5倍。
近期,国内百度深度学习平台飞桨发布了在Graphcore IPU上实现训练和推理全流程支持的开源代码库,百度飞桨的开发者可以在IPU上进行AI模型加速。国内的开发者小伙伴们不妨试试看IPU的加速效果。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )