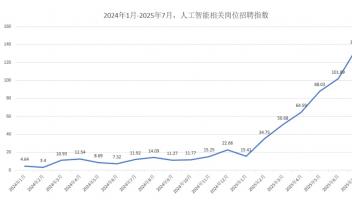
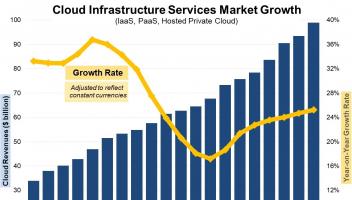
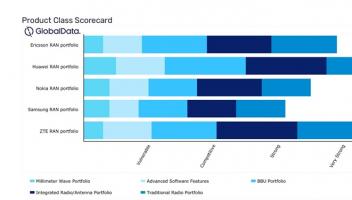
深度求索于8月21日正式发布新一代大模型 DeepSeek-V3.1,该版本在架构设计、推理效率、智能体能力等方面进行了多项重要升级,并同步开放了模型权重及API服务。这一发布再度引发行业对AI智能体发展阶段的关注:DeepSeek-V3.1 所标榜的“Agent能力增强”,究竟是技术突破,还是市场宣传的又一概念包装?
从技术架构来看,DeepSeek-V3.1 提出“混合推理”机制,允许用户在思考模式(think mode)与非思考模式间自由切换。在思考模式下,模型通过对思维链进行压缩训练,显著减少推理所需的token数量,官方称在多项任务中token消耗降低20%至50%,而性能仍与前一版本R1-0528持平。这一改进不仅提升了响应速度,也降低了推理成本,体现出工程优化方面的实质性进展。
在智能体任务支持方面,新模型强调了对工具调用与多步任务处理能力的增强。根据官方测评,V3.1在编程类任务(如SWE-bench、Terminal-Bench)和复杂搜索任务(如browsecomp、HLE)中表现显著优于前代模型。这类任务通常要求模型理解上下文、调用外部工具(如终端、搜索引擎)、并进行多轮规划与验证。从结果上看,V3.1确实在部分场景中缩短了任务完成所需轮数,显示出一定的流程控制与自我纠错能力。
此外,该模型扩展上下文至128K,并增强了对Function Calling的strict模式支持,提升了API调用的规范性和稳定性。同时,平台也新增了对Anthropic API格式的兼容,降低了已有Claude Code框架用户的迁移成本。这些改动虽属渐进式优化,但对开发者生态具有实际意义。
然而,是否因此就能断言“AI Agent时代”已经到来,仍需冷静看待。当前所谓“智能体”仍大多属于定向任务自动化的范畴,其泛化能力、对真实环境的适应力、以及长期规划能力,与人类对“Agent”的预期仍有差距。尽管V3.1在特定测试集上表现提升,但尚未见到其在开放环境、多模态交互或高风险决策等复杂场景中的验证报告。
另一方面,模型的开源策略也值得关注。DeepSeek此次同时释出了Base模型与经过后训练(Post-Training)的模型权重,涵盖Hugging Face与魔搭平台,并采用FP8量化策略以降低部署门槛。这一做法有利于技术透明与社区共建,但也对使用者提出了更高的适配要求,因其分词器与模板机制相较V3版本存在较大变更。
伴随模型更新,深度求索也宣布自2025年9月6日起调整API定价结构并取消夜间优惠,这一商业决策可能对中小开发团队及研究机构的使用成本产生影响。在技术推进的同时,企业也需在普惠性与可持续经营之间找到平衡。
总体而言,DeepSeek-V3.1 在推理效率、任务完成能力和工程可用性方面均实现了可衡量的进步,其“混合架构”与“增强版Agent”并非空谈。然而,是否称得上“Agent时代的突破”,则取决于我们如何定义“Agent”。若以工具调用与有限自动化为标准,V3.1无疑向前迈进了一步;若以通用智能体为终局,则当前成果仍处于量变积累阶段。只有持续在真实场景中验证其可靠性,技术演进才不至沦为营销话语中的“噱头”。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )