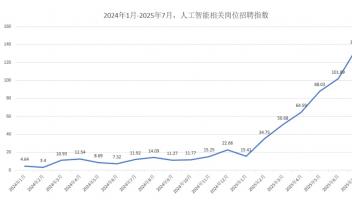
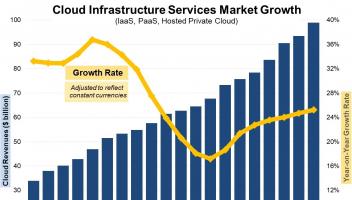
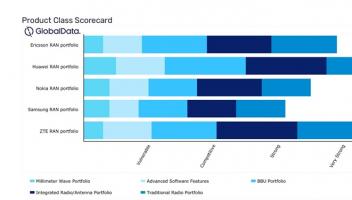
近日,深度求索(DeepSeek)正式发布新一代大模型 DeepSeek-V3.1,并首次公开提及采用“UE8M0 FP8 Scale”参数精度。这一技术细节的披露,迅速引发行业关注。官方在公众号文章中进一步解释,UE8M0 FP8 是专为下一代国产芯片设计的浮点数格式,旨在提升计算效率并降低资源消耗。这一表述,被外界解读为 DeepSeek 在软硬件协同优化方面的战略布局,也让人不禁思考:在AI芯片竞争日趋激烈的背景下,国产新芯是否真的能够借此实现技术破局?
从技术层面来看,FP8(8位浮点数)并非全新概念。它属于IEEE浮点算术标准中的一种数据类型,相比传统FP16或FP32,能在保持相对较高数值精度的同时,显著减少内存占用和计算开销,尤其适合大规模AI推理与训练。而“UE8M0”这一命名,则体现出其定制化特性——根据官方表述,它针对国产芯片架构做了专门优化。这一点至关重要,因为它不仅涉及算法与硬件的适配,更可能影响到整个AI计算生态的构建。
目前,全球AI芯片市场仍由英伟达(NVIDIA)主导,其GPU配合CUDA生态几乎成为大模型训练的事实标准。而国内虽有多家企业投入AI芯片研发,如华为昇腾、寒武纪、天数智芯等,但在软件栈、开发者工具、模型兼容性等方面仍面临挑战。DeepSeek 此次明确将模型精度与“国产芯片”进行绑定,显示出一种推动国产化全栈技术发展的意图。通过从模型层面主动适配新型硬件,或许能在一定程度上缓解国产芯片在生态支持上的不足。
此外,DeepSeek-V3.1 本身也体现出显著的技术进步。据官方信息,其Base模型在V3基础上新增训练了840B tokens,模型规模与性能进一步提升。同时,团队将Base模型及经过后训练的完整模型均在Hugging Face和魔搭ModelScope平台开源,体现出较强的开放性和社区共建意识。这一做法有助于吸引更多开发者参与测试、优化乃至应用于实际场景,从而加速技术迭代与应用落地。
然而,能否真正实现“破局”,仍存在多方面挑战。首先,国产芯片在制程工艺、内存带宽、互联技术等硬件基础上与国际顶尖水平仍存差距。其次,软件生态的成熟非一日之功,需要芯片厂商、算法公司、应用开发者共同长期投入。再者,国际市场政策环境的不确定性,也可能影响相关技术的全球推广与合作。
总体来看,DeepSeek 此次发布不仅是一次模型升级,更可视为对国产AI计算体系的一次重要推动。通过模型与芯片的协同设计,有望在特定场景下实现更高效的计算,并逐步减少对国外技术的依赖。但能否真正打破现有市场格局,仍需看后续硬件性能、软件适配、开发者接受度以及商业落地等多方面的实际表现。
国产芯片的崛起绝非单点突破所能实现,它需要产业链上下游的紧密配合与持续创新。DeepSeek-V3.1 及其所代表的软硬件协同策略,或许正是这条长路上的重要一步。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )