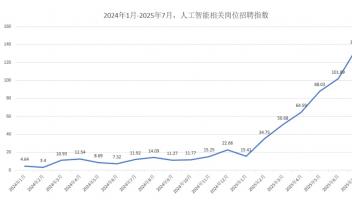
极客网·人工智能8月21日 国家数据局发布数据显示,当前国内多数 AI 模型训练所用中文数据占比已超 60%,部分模型更是达到 80%。中文高质量数据供给能力的持续增强,成为我国 AI 模型性能快速提升的关键支撑。
国家数据局局长刘烈宏指出,我国 AI 的高速发展离不开对数据工作的高度重视,数据作为 AI 核心要素,在推进 “人工智能 +” 中作用关键,高质量数据集建设尤为重要。他还提到,AI 时代的 “Token(词元)” 是文本处理的最小数据单元,类似互联网时代的 “流量”。2024 年初我国日均 Token 消耗量为 1000 亿,至 2025 年 6 月底已突破 30 万亿,一年半内增长超 300 倍,直观反映出国内 AI 应用规模的迅猛扩张。
截至 2025 年 6 月底,我国已建成超 3.5 万个高质量数据集,总体量超 400PB(1PB 约可存储 5 亿张 2MB 高清照片),该规模相当于中国国家图书馆数字资源总量的 140 倍。与此同时,AI 模型训练带动数据交易需求攀升,各地高质量数据集累计交易额近 40 亿元,数据交易机构挂牌的高质量数据集总规模达 246PB。
下一步,国家数据局将通过体系化布局推进高质量数据集建设,加快打造具身智能、低空经济、生物制造等重点领域数据高地,推动社会强化数据要素价值认同,促进数据要素价值共创,培育 “为优质数据买单” 的市场共识。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )